In computer science, a cache is a collection of data
duplicating original values stored elsewhere or computed earlier, where the
original data is expensive to fetch (owing to longer access time) or to compute,
compared to the cost of reading the cache. In other words, a cache is a
temporary storage area where frequently accessed data can be stored for rapid
access. Once the data is stored in the cache, it can be used in the future by
accessing the cached copy rather than re-fetching or recomputing the original
data.
A cache has proven to be extremely effective in many areas of
computing because access patterns in typical computer applications have locality
of reference. There are several kinds of locality, but this article primarily
deals with data that are accessed close together in time (temporal locality).
The data might or might not be located physically close to each other (spatial
locality).
History
Use of the word cache in the computer context
originated in 1967 during preparation of an article for publication in the IBM
Systems Journal. The paper concerned an exciting memory improvement in Model 85,
a latecomer in the IBM System/360 product line. The Journal editor, Lyle R.
Johnson, pleaded for a more descriptive term than high-speed buffer. When none
was forthcoming, he suggested the noun cache, from the French noun meaning a
safekeeping or storage place . The paper was published in early 1968, the
authors were honored by IBM, their work was widely welcomed and subsequently
improved upon, and cache soon became standard usage in computer
literature.
Operation
A cache is a block of memory for temporary storage of data
likely to be used again. The
CPU
and hard drive frequently use a cache, as do web browsers and web servers.
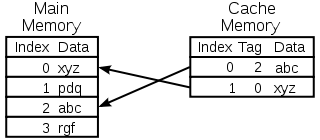
A cache is made up of a pool of entries. Each entry has a
datum (a nugget of data) which is a copy of the datum in some backing store.
Each entry also has a tag, which specifies the identity of the datum in the
backing store of which the entry is a copy.
When the cache client (a CPU, web browser, operating system)
wishes to access a datum presumably in the backing store, it first checks the
cache. If an entry can be found with a tag matching that of the desired datum,
the datum in the entry is used instead. This situation is known as a cache hit.
So, for example, a web browser program might check its local cache on disk to
see if it has a local copy of the contents of a web page at a particular URL. In
this example, the URL is the tag, and the contents of the web page is the datum.
The percentage of accesses that result in cache hits is known as the hit rate or
hit ratio of the cache.
The alternative situation, when the cache is consulted and
found not to contain a datum with the desired tag, is known as a cache miss. The
previously uncached datum fetched from the backing store during miss handling is
usually copied into the cache, ready for the next access.
During a cache miss, the CPU usually ejects some other entry
in order to make room for the previously uncached datum. The heuristic used to
select the entry to eject is known as the replacement policy. One popular
replacement policy, least recently used (LRU), replaces the least recently used
entry (see cache algorithms). More efficient caches compute use frequency
against the size of the stored contents, as well as the latencies and
throughputs for both the cache and the backing store. While this works well for
larger amounts of data, long latencies, and slow throughputs, such as
experienced with a hard drive and the Internet, it's not efficient to use this
for cached main memory (RAM).
When a datum is written to the cache,
it must at some point be written to the backing store as well. The timing of
this write is controlled by what is known as the write policy.
In a write-through cache, every write to the cache causes a
synchronous write to the backing store.
Alternatively, in a write-back (or write-behind) cache,
writes are not immediately mirrored to the store. Instead, the cache tracks
which of its locations have been written over (these locations are marked
dirty). The data in these locations is written back to the backing store when
those data are evicted from the cache, an effect referred to as a lazy write.
For this reason, a read miss in a write-back cache (which requires a block to be
replaced by another) will often require two memory accesses to service: one to
retrieve the needed datum, and one to write replaced data from the cache to the
store.
Data write-back may be triggered by other policies as well.
The client may make many changes to a datum in the cache, and then explicitly
notify the cache to write back the datum.
No-write allocation is a cache policy where only processor
reads are cached, thus avoiding the need for write-back or write-through when
the old value of the datum was absent from the cache prior to the write.
The data in the backing store may be changed by entities
other than the cache, in which case the copy in the cache may become out-of-date
or stale. Alternatively, when the client updates the data in the cache, copies
of that data in other caches will become stale. Communication protocols between
the cache managers which keep the data consistent are known as coherency
protocols.
Applications
CPU cache
Small memories on or close to the
CPU
can be made faster than the much larger main memory. Most CPUs since the 1980s
have used one or more caches, and modern microprocessors inside personal
computers may have as many as half a dozen, each specialized to a different part
of the task of executing programs.
Disk cache
While CPU caches are generally managed entirely by hardware,
other caches are managed by a variety of software. The page cache in main
memory, which is an example of disk cache, is usually managed by the operating
system kernel.
While the hard drive's hardware disk buffer is sometimes
misleadingly referred to as "disk cache", its main functions are write
sequencing and read prefetching. Repeated cache hits are relatively rare, due to
the small size of the buffer in comparison to HDD's capacity.
In turn, fast local hard disk can be used to cache
information held on even slower data storage devices, such as remote servers
(web cache) or local tape drives or optical jukeboxes. Such a scheme is the main
concept of hierarchical storage management.
Web cache
Web caches are employed byweb browsers and web proxy servers
to store previous responses from web servers, such as web pages. Web caches
reduce the amount of information that needs to be transmitted across the
network, as information previously stored in the cache can often be re-used.
This reduces bandwidth and processing requirements of the web server, and helps
to improve responsiveness for users of the web.
Modern web browsers employ a built-in web cache, but some
internet service providers or organizations also use a caching proxy server,
which is a web cache that is shared between all users of that network.
Another form of cache isP2P caching, where the files most
sought for by Peer-to-peer applications are stored in an ISP cache to accelerate
P2P transfers.
Other Caches
The BIND DNS daemon caches a mapping of domain names to IP
addresses, as does a resolver library.
Write-through operation is common when operating over
unreliable networks (like an Ethernet LAN), because of the enormous complexity
of the coherency protocol required between multiple write-back caches when
communication is unreliable. For instance, web page caches and client-side
network file system caches (like those in NFS or SMB) are typically read-only or
write-through specifically to keep the network protocol simple and reliable.
Search engines also frequently make web pages they have indexed available from
their cache. For example, Google provides a "Cached" link next to each search
result. This is useful when web pages are temporarily inaccessible from a web
server.
Another type of caching is storing computed results that will
likely be needed again, or memoization. An example of this type of caching is
ccache, a program that caches the output of the compilation to speed up the
second-time compilation.
Database caching can substantially improve the throughput of database
applications, for example in the processing of indexes, data dictionaries, and
frequently used subsets of data.
The difference between buffer and cache
The terms are not mutually exclusive and the functions are
frequently combined; however, there is a difference in intent. A buffer is a
temporary memory location, that is traditionally used because CPU instructions
cannot directly address data stored in peripheral devices. Thus, addressable
memory is used as intermediate stage.
Additionally such a buffer may be feasible when a large block
of data is assembled or disassembled (as required by a storage device), or when
data may be delivered in a different order than that in which it is produced.
Also a whole buffer of data is usually transferred sequentially (for example to
hard disk), so buffering itself sometimes increases transfer performance. These
benefits are present even if the buffered data are written to the buffer once
and read from the buffer once.
A cache also increases transfer performance. A part of the
increase similarly comes from the possibility that multiple small transfers will
combine into one large block. But the main performance gain occurs because there
is a good chance that the same datum will be read from cache multiple times, or
that written data will soon be read. A cache's sole purpose is to reduce
accesses to the underlying slower storage. Cache is also usually an abstraction
layer that is designed to be invisible from the perspective of neighboring
layers.

){kind=link}